W tym artykule przedstawiono rozwiązanie wbudowanego cyfrowego systemu emisji głosu w sieci Ethernet, które może z łatwością realizować funkcję nadawania regionalnego systemu nadawczego. System jest oparty na architekturze ramienia i przyjmuje metodę arbitrażu terminala odtwarzania systemu w celu sterowania realizacją transmisji regionalnej, a treść transmisji może być odtwarzana i zapisywana jednocześnie.
Cyfrowy system rozgłaszania głosu w sieci Ethernet odnosi się głównie do systemu rozgłaszania wykorzystującego Ethernet jako medium transmisyjne do świadczenia usług audio. Ethernet można wykorzystać do rozwiązania problemu przesyłania sygnałów głosowych na duże odległości. Umożliwia projektantom tworzenie wielkoskalowych struktur sieciowych w celu realizacji transmisji tysięcy cyfrowych sygnałów głosowych w sieci Ethernet, w pełni wykorzystując istniejące zasoby sieciowe, unikając problemów związanych z wielokrotnym konfigurowaniem linii oraz realizując integrację sieci rozgłoszeniowych i komputerowych . Rozwiązuje problemy niskiej jakości dźwięku, podatności na zakłócenia, skomplikowanej konserwacji i zarządzania oraz słabej interakcji w tradycyjnych systemach nadawczych. Jednocześnie możliwe jest wybranie wszystkich, części lub określonych obszarów do kierunkowego nadawania grupowego, co przełamuje ograniczenie polegające na tym, że tradycyjne systemy nadawcze mogą wykonywać nadawanie publiczne tylko na wszystkich obszarach. Istniejące cyfrowe systemy rozgłaszania głosu w sieci Ethernet przeważnie wykorzystują sygnały sterujące do sterowania terminalem rozgłoszeniowym w celu dołączenia lub opuszczenia grupy rozsyłania grupowego w celu realizacji funkcji nadawania regionalnego. Konieczne jest wysłanie sygnału sterującego, aby terminal dołączył do grupy multiemisji, zanim będzie można zrealizować rozgłaszanie. Lub ustanowienie złożonej tabeli mapowania po stronie serwera, aby utrzymać stan terminala odtwarzającego w celu uzyskania transmisji regionalnej, która jest bardziej skomplikowana do wdrożenia.
1 Projekt konstrukcyjny
System ten przyjmuje strukturę C / S, składa się z dwóch części końcowego serwera systemu rozgłoszeniowego i terminala rozgłoszeniowego systemu rozgłoszeniowego, jak pokazano na fig. 1.
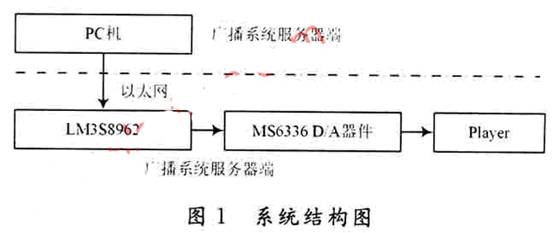
Serwer systemu rozgłoszeniowego zaimplementowany jest na komputerze PC i jest to program gromadzenia, przechowywania i transmisji sygnałów głosowych realizowany przez VC ++. Ta część zbiera i przechowuje sygnał głosowy przez mikrofon, a następnie przesyła dane głosowe do sieci Ethernet za pośrednictwem protokołu UDP, aby zrealizować funkcję transmisji danych głosowych w sieci.
Terminal odtwarzania systemu rozgłoszeniowego jest terminalem wbudowanym opartym na LM3S8962, który może odbierać pakiety danych głosowych IP wysyłanych do niego z sieci Ethernet, a układ dekodowania dźwięku MS6336 kończy konwersję cyfrową / analogową i odtwarzanie danych głosowych
2 Projekt sprzętu terminala rozgłoszeniowego systemu nadawczego
Główny układ sterujący terminala rozgłoszeniowego systemu rozgłoszeniowego wykorzystuje mikrokontroler LM3S8962 dostarczony przez LuminaryMicro. Ta seria chipów jest pierwszym kontrolerem opartym na ARM CortexTM-M3 z wewnętrznym zintegrowanym kontrolerem Ethernet. Jest to pierwszy w branży układ ARM, który obsługuje Industrial Ethernet (IEEE) i może z łatwością implementować funkcje sieciowe.
Układ dekodera audio wykorzystuje układ MS6336 wyprodukowany przez MOSA. Układ jest 16-bitowym stereofonicznym konwerterem cyfrowo-analogowym audio, a obsługiwane formaty wejścia cyfrowego to Right Justifl-ed, Left Justified, I2S. Interfejs sterowania MS6336 przyjmuje magistralę I2C, interfejs jest łatwy do ustawienia. Część DAC ma dokładny i stabilny prąd, w połączeniu z doskonałą metodą symetrycznego dekodowania, może odtwarzać wysokiej jakości sygnały audio.
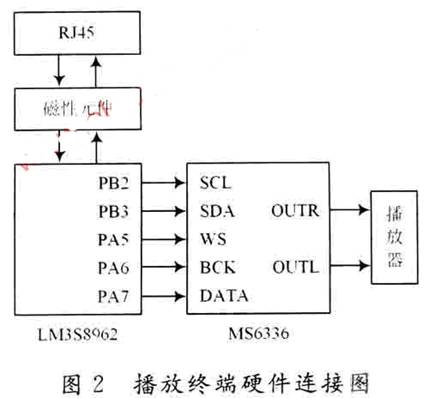
Główny układ sterujący LM3S8962 jest podłączony do interfejsu RJ45 za pomocą elementów magnetycznych i służy do odbierania danych głosowych z sieci Ethernet. LM3S8962 zapewnia sygnały sterujące i sygnały danych głosowych dla układu dekodera audio MS6336. LM3S8962 obsługuje funkcję I2C. Porty PB2 i PB3 zapewniają odpowiednio zegar I2C i sygnały danych. Te dwa piny mogą być bezpośrednio podłączone do pinów funkcyjnych I2C MS6336 i wymagany jest rezystor podciągający. LM3S8962 nie obsługuje formatu wprowadzania danych wymaganego przez MS6336. Format wprowadzania danych MS6336 w systemie przyjmuje I2S. Dlatego, aby dostarczyć dane głosowe do MS6336, konieczne jest użycie oprogramowania portu GPIO LM3S8962 do symulacji formatu wejścia danych I2S wymaganego przez MS6336. W projekcie porty PA5, PA6 i PA7 są używane do symulacji tej funkcji. Trzy piny odpowiadają odpowiednio sygnałowi wyboru kanału I2S, sygnałowi zegara i sygnałowi danych. Podłącz te trzy piny do pinu funkcji I2S w MS6336.
Strukturę sprzętową terminala odtwarzającego cyfrowego systemu rozgłaszania głosu Ethernet przedstawiono na rysunku 2.
3 Projektowanie oprogramowania systemu nadawczego
Oprogramowanie systemu rozgłoszeniowego jest podzielone na dwie części: oprogramowanie serwera systemu rozgłoszeniowego i oprogramowanie terminala rozgłoszeniowego.
Ten projekt realizuje odtwarzanie danych głosowych w czasie rzeczywistym, więc wymagana jest wydajność transmisji danych głosowych w czasie rzeczywistym, ale wymagania dotyczące integralności danych nie są zbyt surowe, a niewielka utrata pakietów nie wpłynie na ogólny efekt odtwarzania, czyli dane głosowe systemu Transmisja przyjmuje tryb transmisji UDP. Jednocześnie system działa w sieci lokalnej i jest niewielu użytkowników tymczasowych. Dlatego przydział statycznego adresu IP jest stosowany w celu uproszczenia realizacji oprogramowania terminala odtwarzającego.
3.1 Gromadzenie, przechowywanie i transmisja danych głosowych po stronie serwera systemu nadawczego
Zbieranie danych głosowych jest realizowane za pomocą niskopoziomowych funkcji API audio WAVE. Aby nie powodować utraty danych głosowych, projekt wykorzystuje podwójne buforowanie do przechowywania danych głosowych. Proces wdrażania przedstawiono na rysunku 3.
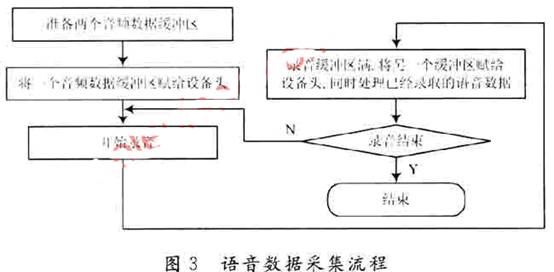
Po zapełnieniu jednego bufora rejestracyjnego system natychmiast wysyła kolejny bufor rejestracyjny do urządzenia rejestrującego w celu kontynuacji nagrywania, a aplikacja powinna odczytać dane w pełnym buforze rejestracyjnym i je przetworzyć. Następnie wywołaj funkcję waveInAddBuffer, aby ponownie przypisać bufor do urządzenia rejestrującego w celu ponownego wykorzystania.
Aby nie dopuścić do utraty danych głosowych w procesie nagrywania, nie wystarczy po prostu zastosować podwójne buforowanie. Należy również zauważyć, że gdy jeden bufor jest pełny, aplikacja będzie przetwarzać dane w buforze a drugi Bufor jest używany do rejestracji, a czas przetwarzania danych musi być krótszy niż czas wymagany do pełnego zapełnienia drugiego bufora nagrane, w przeciwnym razie pierwszy bufor nie zostanie ponownie przypisany do urządzenia rejestrującego po zapełnieniu drugiego bufora, co spowoduje utratę danych głosowych. Gdy częstotliwość próbkowania sygnału głosowego jest duża, odpowiednie zwiększenie rozmiaru bufora może skutecznie rozwiązać ten problem.
Aby zachować nadawane treści do późniejszego wykorzystania, konieczne jest zapisanie nadawanych treści w pliku WAV. Pliki WAV mają stały format nagłówka. Przed zapisaniem danych głosowych należy ustawić nagłówek pliku WAV, w przeciwnym razie zapisany plik WAV nie będzie mógł zostać odtworzony. Za każdym razem, gdy bufor nagrywania jest pełny, najpierw znajdź koniec pliku WAV, a następnie po kolei zapisz zebrane dane na końcu pliku. Po zakończeniu całego procesu nadawania wszystkie dane głosowe są zapisywane w pliku WAV, realizując przechowywanie danych głosowych.
Gdy bufor nagrywania jest pełny, konieczne jest przesłanie zebranych danych głosowych przez sieć. W projekcie najpierw użyj klasy Csocket, aby utworzyć gniazdo, a następnie wystarczy zahermetyzować zebrane dane w pakiecie IP i wysłać go. Częstotliwość próbkowania sygnału głosowego w tej konstrukcji wynosi 44.1 kHz, 16-bitowy dwukanałowy. Aby uniknąć utraty danych głosowych, rozmiar bufora nagrywania jest ustawiony na 1024B.
3.2 Realizacja nadawania regionalnego
Ważnym zastosowaniem systemu cyfrowej rozgłaszania głosu Ethernet jest nie tylko realizacja rozgłaszania całego obszaru, ale także realizacja funkcji rozgłaszania lokalnego, czyli nadawanie do wyznaczonego terminala. Dlatego pakiet multiemisji UDP jest używany do transmisji danych w sieciowej transmisji głosowych pakietów danych IP. Wykorzystując pakiety multicast do transmisji danych, wszystkie terminale należące do grupy w sieci lokalnej mogą odbierać dane, realizując rozgłaszanie całego obszaru. Aby zrealizować lokalną funkcję rozgłoszeniową, przed danymi głosowymi w projekcie dodawana jest struktura, jak pokazano poniżej, a plik konfiguracyjny jest używany do przechowywania adresu IP każdego terminala systemu.
02 Projektowanie sprzętu terminala nadawczego systemu nadawczego
Główny układ sterujący terminala rozgłoszeniowego systemu rozgłoszeniowego wykorzystuje mikrokontroler LM3S8962 dostarczony przez LuminaryMicro. Ta seria chipów jest pierwszym kontrolerem opartym na ARM CortexTM-M3 z wewnętrznym zintegrowanym kontrolerem Ethernet. Jest to pierwszy w branży układ ARM, który obsługuje Industrial Ethernet (IEEE) i może z łatwością implementować funkcje sieciowe.
Układ dekodera audio wykorzystuje układ MS6336 wyprodukowany przez MOSA. Układ jest 16-bitowym stereofonicznym konwerterem cyfrowo-analogowym audio, a obsługiwane formaty wejścia cyfrowego to Right Justifl-ed, Left Justified, I2S. Interfejs sterowania MS6336 przyjmuje magistralę I2C, interfejs jest łatwy do ustawienia. Część DAC ma dokładny i stabilny prąd, w połączeniu z doskonałą metodą symetrycznego dekodowania, może odtwarzać wysokiej jakości sygnały audio.
Główny układ sterujący LM3S8962 jest podłączony do interfejsu RJ45 za pomocą elementów magnetycznych i służy do odbierania danych głosowych z sieci Ethernet. LM3S8962 zapewnia sygnały sterujące i sygnały danych głosowych dla układu dekodera audio MS6336. LM3S8962 obsługuje funkcję I2C. Porty PB2 i PB3 zapewniają odpowiednio zegar I2C i sygnały danych. Te dwa piny mogą być bezpośrednio podłączone do pinów funkcyjnych I2C MS6336 i wymagany jest rezystor podciągający. LM3S8962 nie obsługuje formatu wprowadzania danych wymaganego przez MS6336. Format wprowadzania danych MS6336 w systemie przyjmuje I2S. Dlatego, aby dostarczyć dane głosowe do MS6336, konieczne jest użycie oprogramowania portu GPIO LM3S8962 do symulacji formatu wejścia danych I2S wymaganego przez MS6336. W projekcie porty PA5, PA6 i PA7 są używane do symulacji tej funkcji. Trzy piny odpowiadają odpowiednio sygnałowi wyboru kanału I2S, sygnałowi zegara i sygnałowi danych. Podłącz te trzy piny do pinu funkcji I2S w MS6336.
Strukturę sprzętową terminala odtwarzającego cyfrowego systemu rozgłaszania głosu Ethernet przedstawiono na rysunku 2.
3 Projektowanie oprogramowania systemu nadawczego
Oprogramowanie systemu rozgłoszeniowego jest podzielone na dwie części: oprogramowanie serwera systemu rozgłoszeniowego i oprogramowanie terminala rozgłoszeniowego.
Ten projekt realizuje odtwarzanie danych głosowych w czasie rzeczywistym, więc wymagana jest wydajność transmisji danych głosowych w czasie rzeczywistym, ale wymagania dotyczące integralności danych nie są zbyt surowe, a niewielka utrata pakietów nie wpłynie na ogólny efekt odtwarzania, czyli dane głosowe systemu Transmisja przyjmuje tryb transmisji UDP. Jednocześnie system działa w sieci lokalnej z mniejszą liczbą użytkowników tymczasowych. Dlatego przydział statycznego adresu IP jest stosowany, aby uprościć realizację oprogramowania terminala odtwarzającego.
3.1 Gromadzenie, przechowywanie i transmisja danych głosowych po stronie serwera systemu nadawczego
Zbieranie danych głosowych jest realizowane za pomocą niskopoziomowych funkcji API audio WAVE. Aby nie powodować utraty danych głosowych, projekt wykorzystuje podwójne buforowanie do przechowywania danych głosowych. Proces wdrażania przedstawiono na rysunku 3.
Po zapełnieniu jednego bufora rejestracyjnego system natychmiast wysyła kolejny bufor rejestracyjny do urządzenia rejestrującego w celu kontynuacji nagrywania, a aplikacja powinna odczytać dane w pełnym buforze rejestracyjnym i je przetworzyć. Następnie wywołaj funkcję waveInAddBuffer, aby ponownie przypisać bufor do urządzenia rejestrującego w celu ponownego wykorzystania.
Aby nie dopuścić do utraty danych głosowych w procesie nagrywania, nie wystarczy po prostu zastosować podwójne buforowanie. Należy również zauważyć, że gdy jeden bufor jest pełny, aplikacja będzie przetwarzać dane w buforze a drugi Bufor jest używany do rejestracji, a czas przetwarzania danych musi być krótszy niż czas wymagany do pełnego zapełnienia drugiego bufora nagrane, w przeciwnym razie pierwszy bufor nie zostanie ponownie przypisany do urządzenia rejestrującego po zapełnieniu drugiego bufora, co spowoduje utratę danych głosowych. Gdy częstotliwość próbkowania sygnału głosowego jest duża, odpowiednie zwiększenie rozmiaru bufora może skutecznie rozwiązać ten problem.
Aby zachować nadawane treści do późniejszego wykorzystania, konieczne jest zapisanie nadawanych treści w pliku WAV. Pliki WAV mają stały format nagłówka. Przed zapisaniem danych głosowych należy ustawić nagłówek pliku WAV, w przeciwnym razie zapisany plik WAV nie będzie mógł zostać odtworzony. Za każdym razem, gdy bufor nagrywania jest pełny, najpierw znajdź koniec pliku WAV, a następnie po kolei zapisz zebrane dane na końcu pliku. Po zakończeniu całego procesu nadawania wszystkie dane głosowe są zapisywane w pliku WAV, realizując przechowywanie danych głosowych.
Gdy bufor nagrywania jest pełny, konieczne jest przesłanie zebranych danych głosowych przez sieć. W projekcie najpierw użyj klasy Csocket, aby utworzyć gniazdo, a następnie wystarczy zahermetyzować zebrane dane w pakiecie IP i wysłać go. Częstotliwość próbkowania sygnału głosowego w tej konstrukcji wynosi 44.1 kHz, 16-bitowy dwukanałowy. Aby uniknąć utraty danych głosowych, rozmiar bufora nagrywania jest ustawiony na 1024B.
3.2 Realizacja nadawania regionalnego
Ważnym zastosowaniem systemu cyfrowej rozgłaszania głosu Ethernet jest nie tylko realizacja rozgłaszania całego obszaru, ale także realizacja funkcji rozgłaszania lokalnego, czyli nadawanie do wyznaczonego terminala. Dlatego pakiet multiemisji UDP jest używany do transmisji danych w sieciowej transmisji głosowych pakietów danych IP. Wykorzystując pakiety multicast do transmisji danych, wszystkie terminale należące do grupy w sieci lokalnej mogą odbierać dane, realizując rozgłaszanie całego obszaru. Aby zrealizować lokalną funkcję rozgłoszeniową, przed danymi głosowymi w projekcie dodawana jest struktura, jak pokazano poniżej, a plik konfiguracyjny jest używany do przechowywania adresu IP każdego terminala systemu.
STRING STRING
{Ciąg IPNO1;
Ciąg IPNO2;
...
Ciąg IPNO9;
Ciąg IPNO10};
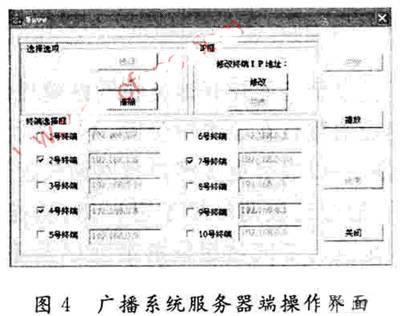
Kiedy konieczne jest wykonanie regionalnej transmisji na niektórych terminalach, wybierz odpowiednie numery tych terminali na panelu po stronie serwera systemu nadawczego (jak pokazano na rysunku 4). W tym momencie adres IP wybranego terminala jest odczytywany z pliku konfiguracyjnego i przypisywany do odpowiedniej zmiennej w strukturze. Kiedy terminal odbiera pakiet multiemisji IP, najpierw ocenia, czy struktura ma taką samą zmienną jak jego własny adres IP, jeśli tak, to dane są odbierane i odtwarzane, jeśli nie, dane są odrzucane, realizując w ten sposób obszar Broadcast funkcjonować. W porównaniu ze sposobem wykorzystania sygnału sterującego do sterowania terminalem odtwarzania w celu dołączenia lub opuszczenia grupy rozsyłania grupowego lub do dynamicznego utrzymywania złożonej tabeli mapowania w celu implementacji funkcji transmisji regionalnej. Ten sposób nie musi interaktywnie sterować terminalem odtwarzającym przed każdą transmisją, ani też nie musi dynamicznie śledzić stanu terminala. Wystarczy wpisać odpowiedni adres IP terminala do pliku konfiguracyjnego, gdy terminal łączy się z systemem po raz pierwszy. Funkcja jest prosta do wdrożenia.
3.3 Wykonanie oprogramowania terminala rozgłoszeniowego systemu rozgłoszeniowego
Terminal nadawczy systemu rozgłoszeniowego jest podzielony na dwie części w celu realizacji, część odbierająca dane audio jest wykorzystywana do odbierania danych głosowych oraz przechowywania i przekazywania, a dekoder audio realizuje konwersję cyfrowo-analogową i odtwarzanie sygnału głosowego. Część odbierająca dane audio przyjmuje programowanie przez gniazdo w celu odbierania danych głosowych z sieci Ethernet. Po odebraniu pakietu danych głosowych musi najpierw ocenić, czy pakiet danych jest przeznaczony dla siebie. Terminal porównuje zmienną składową struktury STRING w pakiecie IP z własnym adresem IP, a jeśli jakakolwiek zmienna składowa jest równa jego własnemu adresowi IP, zapisuje dane w pakiecie, w przeciwnym razie je odrzuca.
Dane głosowe są odbierane i zapisywane w cyklicznej kolejce. Ze względu na zaburzenie transmisji danych UDP, pakiety danych głosowych muszą być sortowane po odebraniu danych głosowych na końcu odbierającym dane głosowe, aby zapewnić sekwencyjne przetwarzanie danych głosowych i prawidłowe odtworzenie sygnału głosowego. Jednocześnie, aby uniknąć fluktuacji sieci, dane są przetwarzane za każdym razem, gdy w kolejce cyklicznej jest co najmniej 5 pakietów.
Format wprowadzania danych MS6336 w projekcie przyjmuje format I2S. Ponieważ LM3S8962 nie obsługuje tego formatu danych, zastosowano symulację oprogramowania w celu realizacji funkcji I2S przez port GPIO. Aby całkowicie przywrócić sygnał głosowy, konieczne jest zapewnienie ścisłego i dokładnego taktowania sygnału I2S, a konwersja między poziomami wysokimi i niskimi jest realizowana przez program opóźniający. Schemat czasowy I2S pokazano na rysunku 5.
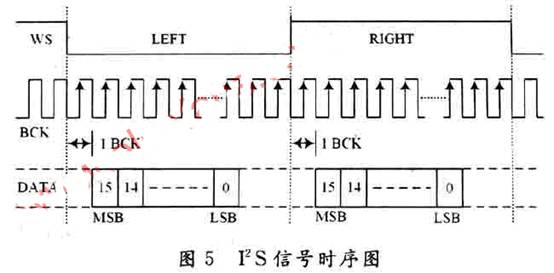
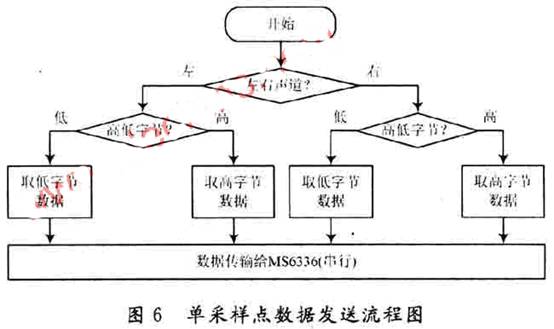
Częstotliwość zegara terminala rozgłoszeniowego systemu rozgłoszeniowego wynosi 40 MHz, a czas wysłania każdego bitu danych wynosi 600 ns obliczony na podstawie częstotliwości próbkowania. LM3S8962 dostarcza dane głosowe do MS6336 i realizuje transmisję szeregową przez port GPIO zgodnie z punktem próbkowania. Każdy punkt próbkowania zawiera cztery bajty, a proces wysyłania danych z punktu próbkowania przedstawiono na rysunku 6.
4 Analiza wyników
Rozmiar pakietu danych głosowych przesyłanych przez system przez Ethernet to 1024B. Aby uniknąć fluktuacji sieci, terminal rozpoczyna nadawanie po odebraniu 5 pakietów danych. Czas opóźnienia nadawania wynosi około 30 ms, co spełnia wskaźniki funkcjonalne. Serwer może sterować pracą 10 terminali nadawczych w tym samym czasie. Wybierając odpowiedni numer terminala po stronie serwera, można z powodzeniem zrealizować funkcje rozgłaszania całego obszaru i rozgłaszania lokalnego systemu nadawczego.
Wnioski 5
Wychodząc od rzeczywistych potrzeb projektujemy i wdrażamy system cyfrowej emisji głosu Ethernet. Wyniki eksperymentalne pokazują, że terminal odtwarzający systemu decyduje o tym, czy przeprowadzić transmisję głosową w celu realizacji transmisji regionalnej, co jest prostym i skutecznym sposobem realizacji globalnego nadawania i regionalnej transmisji sygnałów głosowych. Terminal odtwarzacza systemowego przyjmuje symulację oprogramowania portu GPIO, aby zrealizować funkcję I2S, która może dokładnie zrealizować taktowanie I2S, zakończyć transmisję danych sygnału głosowego i realizować transmisję sygnału głosowego w czasie rzeczywistym. Struktura projektu jest rozsądna i może łatwo realizować rozszerzenie funkcji, takich jak emisja czasowa, odtwarzanie muzyki, zdalne zarządzanie, monitorowanie w czasie rzeczywistym itp. Ten projekt ma ważne znaczenie praktyczne i stanowi podstawę do rozwiązywania dużych i złożonych transmisji Ethernet systemy.
Nasze inne produkty:












