(1) Nadmiarowe informacje o sygnale wideo
Biorąc za przykład format komponentu YUV do nagrywania cyfrowego wideo, YUV reprezentuje odpowiednio jasność i dwa sygnały różnicowe kolorów. Na przykład dla istniejącego systemu pal TV częstotliwość próbkowania sygnału luminancji wynosi 13.5 MHz; pasmo częstotliwości sygnału chrominancji stanowi zwykle połowę lub mniej sygnału jasności, czyli 6.75 MHz lub 3.375 MHz. Biorąc na przykład częstotliwość próbkowania 4: 2: 2, sygnał Y przyjmuje 13.5 MHz, sygnał chrominancji U i V są próbkowane z częstotliwością 6.75 MHz, a sygnał próbkowania jest kwantowany przez 8 bitów, a następnie można obliczyć współczynnik kodowania cyfrowego wideo następująco:
13.5 * 8 + 6.75 * 8 + 6.75 * 8 = 216 Mbit / s
Jeśli tak duża ilość danych jest przechowywana lub przesyłana bezpośrednio, trudno będzie zastosować technologię kompresji w celu zmniejszenia szybkości transmisji. Cyfrowy sygnał wideo można kompresować zgodnie z dwoma podstawowymi warunkami:
L. redundancja danych. Na przykład redundancja przestrzenna, redundancja czasowa, redundancja struktury, redundancja entropii informacji itp., To znaczy istnieje silna korelacja między pikselami obrazu. Wyeliminowanie tej nadmiarowości nie prowadzi do utraty informacji i jest to bezstratna kompresja.
L. wizualna redundancja. Niektóre cechy ludzkiego oka, takie jak próg rozróżniania jasności, próg widzenia, różnią się wrażliwością na jasność i nasycenie barwy, co uniemożliwia wprowadzenie odpowiednich błędów w kodowaniu i nie zostaną wykryte. Wizualne cechy ludzkich oczu można wykorzystać do wymiany danych na kompresję z pewnymi obiektywnymi zniekształceniami. Ta kompresja jest stratna.
Kompresja cyfrowego sygnału wideo opiera się na dwóch powyższych warunkach, co powoduje, że dane wideo są silnie kompresowane, co sprzyja transmisji i przechowywaniu. Typowe metody cyfrowej kompresji wideo to kodowanie mieszane, które polega na połączeniu kodowania transformacyjnego, przewidywania ruchu i kompensacji ruchu oraz kodowania entropijnego w celu kompresji kodowania. Zwykle do wyeliminowania nadmiarowości wewnątrzramkowej obrazu stosuje się kodowanie transformacyjne, a przewidywanie ruchu i kompensacja ruchu są wykorzystywane do usuwania nadmiarowości między klatkami obrazu, a kodowanie entropijne jest wykorzystywane do dalszej poprawy wydajności kompresji. Poniżej przedstawiono pokrótce trzy metody kodowania kompresyjnego.
(a) Metoda kodowania kompresji
(b) Kodowanie przekształceń
Funkcją kodowania transformacyjnego jest transformacja sygnału obrazu opisanego w dziedzinie przestrzeni do domeny częstotliwości, a następnie kodowanie transformowanych współczynników. Ogólnie rzecz biorąc, obraz ma silną korelację w przestrzeni, a transformacja do domeny częstotliwości może spowodować dekorelację i koncentrację energii. Wspólna transformata ortogonalna obejmuje dyskretną transformatę Fouriera, dyskretną transformację kosinusową i tak dalej. Dyskretna transformata kosinusowa jest szeroko stosowana w cyfrowej kompresji wideo.
Dyskretna transformata kosinusowa jest nazywana transformacją DCT. Może przekształcić blok obrazu L * l z domeny kosmicznej do domeny częstotliwości. Dlatego w procesie kompresji i kodowania obrazu w oparciu o DCT obraz należy podzielić na nienakładające się bloki obrazu. Załóżmy, że rozmiar obrazu to 1280 * 720, jest on podzielony na bloki obrazu 160 * 90 o rozmiarze 8 * 8 bez nakładania się w postaci siatki. Następnie można przeprowadzić transformację DCT dla każdego bloku obrazu.
Po podzieleniu bloku każdy 8 * 8-punktowy blok obrazu jest wysyłany do kodera DCT, a blok obrazu 8 * 8 jest transformowany z domeny przestrzennej do domeny częstotliwości. Poniższy rysunek przedstawia przykład bloku obrazu 8 * 8, w którym liczba reprezentuje wartość jasności każdego piksela. Na rysunku widać, że wartości jasności każdego piksela w tym bloku obrazu są stosunkowo jednolite, zwłaszcza wartość jasności sąsiednich pikseli nie jest zbyt duża, co wskazuje, że sygnał obrazu ma silną korelację.
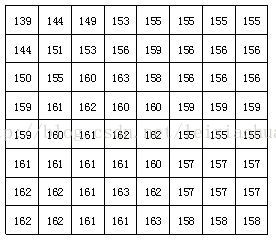
Rzeczywisty blok obrazu 8 * 8
Poniższy rysunek przedstawia wyniki transformacji DCT bloku obrazu na powyższym rysunku. Z rysunku widać, że po transformacji DCT, współczynnik niskiej częstotliwości w lewym górnym rogu skupia dużo energii, podczas gdy energia na współczynniku wysokiej częstotliwości w prawym dolnym rogu jest bardzo mała.
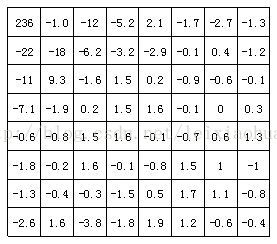
Współczynniki bloku obrazu po transformacji DCT
Sygnał należy określić ilościowo po transformacji DCT. Ponieważ ludzkie oczy są wrażliwe na właściwości obrazów o niskiej częstotliwości, takie jak ogólna jasność obiektów, a nie na szczegóły obrazu o wysokiej częstotliwości, więc w procesie transmisji informacje o wysokiej częstotliwości mogą być przesyłane mniej lub nie, tylko część niskoczęstotliwościowa. Proces kwantyzacji ogranicza transmisję informacji poprzez kwantyfikację współczynników obszaru niskich częstotliwości i zgrubną kwantyzację współczynników w obszarze wysokich częstotliwości, co usuwa informacje o wysokich częstotliwościach, które nie są wrażliwe dla ludzkich oczu. Dlatego kwantyzacja jest stratnym procesem kompresji i głównym powodem pogorszenia jakości kodowania kompresji wideo.
Proces kwantyfikacji można wyrazić następującym wzorem:

Wśród nich FQ (U, V) reprezentuje współczynnik DCT po kwantyzacji; f (U, V) reprezentuje współczynnik DCT przed kwantyzacją; Q (U, V) reprezentuje macierz wag kwantyzacji; q jest krokiem kwantyzacji; round odnosi się do konsolidacji, a wartość do wyprowadzenia jest przyjmowana jako najbliższa wartość całkowita.
Wybierz rozsądnie współczynnik kwantyzacji, a wynik po kwantyzacji transformowanego bloku obrazu jest pokazany na rysunku.

Współczynnik DCT po kwantyfikacji
Większość współczynników DCT jest zmieniana na 0 po kwantyzacji, podczas gdy tylko kilka współczynników ma wartości niezerowe. W tej chwili tylko te niezerowe wartości wymagają kompresji i kodowania.
(b) Kodowanie entropii
Kodowanie entropijne jest nazwane, ponieważ średnia długość kodu po zakodowaniu jest bliska wartości entropii źródła. Kodowanie entropii jest realizowane przez VLC (kodowanie o zmiennej długości). Podstawową zasadą jest nadanie krótkiego kodu symbolowi z dużym prawdopodobieństwem w źródle oraz długi kod symbolowi z małym prawdopodobieństwem wystąpienia, tak aby statystycznie otrzymać krótszą średnią długość kodu. Kodowanie o zmiennej długości zwykle obejmuje kod Hoffmana, kod arytmetyczny, kod uruchomienia itp. Kodowanie długości przebiegu jest bardzo prostą metodą kompresji, jego wydajność kompresji nie jest wysoka, ale szybkość kodowania i dekodowania jest duża i nadal jest szeroko stosowana, zwłaszcza po transformacji kodowania, przy użyciu kodowania run-length, daje dobry efekt.
Najpierw należy zeskanować współczynnik AC bezpośrednio po wyjściowym współczynniku DC kwantyzatora w typie Z (jak pokazano na linii strzałki). Skan Z przekształca dwuwymiarowy współczynnik kwantyzacji w jednowymiarową sekwencję, a następnie kontynuuje kodowanie długości serii. Wreszcie, inny kod o zmiennej długości jest używany do kodowania danych po zakończeniu kodowania, na przykład kodowanie Hoffmana. Dzięki tego rodzaju kodowaniu o zmiennej długości efektywność kodowania jest dalej poprawiana.
(c) Przewidywanie ruchu i kompensacja ruchu
Estymacja ruchu i kompensacja ruchu to skuteczne metody eliminowania korelacji kierunku czasu sekwencji obrazów. Opisane powyżej metody transformacji DCT, kwantyzacji i kodowania entropijnego opierają się na jednym obrazie klatki. Dzięki tym metodom można wyeliminować korelację przestrzenną między pikselami obrazu. W rzeczywistości, oprócz korelacji przestrzennej, sygnał obrazu ma korelację czasową. Na przykład w przypadku cyfrowego wideo ze statycznym tłem, takim jak wspólne nadawanie wiadomości i niewielkim ruchem głównej części obrazu, różnica między każdym obrazem jest bardzo mała, a korelacja między obrazami jest bardzo duża. W takim przypadku nie musimy oddzielnie kodować każdego obrazu klatki, a jedynie kodować możemy tylko zmienione części sąsiednich klatek wideo, aby jeszcze bardziej zmniejszyć ilość danych. Ta praca jest realizowana przez przewidywanie ruchu i kompensację ruchu.
Technologia przewidywania ruchu ogólnie dzieli bieżący obraz wejściowy na kilka małych podbloków obrazu, które nie nakładają się na siebie, na przykład rozmiar obrazu klatki wynosi 1280 * 720. Po pierwsze, jest on podzielony na 40 * 45 bloków obrazu z 16 * 16 rozmiarów, które nie nakładają się na siebie w postaci siatki, a następnie, w ramach okna wyszukiwania poprzedniego obrazu lub tego ostatniego obrazu, znajdź blok dla każdego bloku obrazu, aby znaleźć jeden blok obrazu w zakresie okno wyszukiwania Najbardziej podobny blok obrazu. Proces wyszukiwania nazywa się szacowaniem ruchu. Dzięki obliczeniu informacji o położeniu między najbardziej podobnym blokiem obrazu a blokiem obrazu można uzyskać wektor ruchu. W ten sposób bieżący blok obrazu może zostać odjęty od najbardziej podobnego bloku obrazu wskazywanego przez wektor ruchu obrazu odniesienia i można otrzymać blok obrazu szczątkowego. Ponieważ wartość każdego piksela w bloku obrazu resztkowego jest bardzo mała, w kodowaniu kompresji można uzyskać wyższy współczynnik kompresji. Ten proces odejmowania nazywa się kompensacją ruchu.
Ponieważ obraz odniesienia jest potrzebny do przewidywania ruchu i kompensacji ruchu w procesie kodowania, bardzo ważne jest, aby wybrać obraz odniesienia. Ogólnie, koder dzieli wejście obrazu każdej klatki na trzy różne typy zgodnie z różnymi obrazami odniesienia: ramka I (wewnętrzna), ramka B (predykcja naprowadzania) i ramka P (predykcja). Jak pokazano na rysunku.
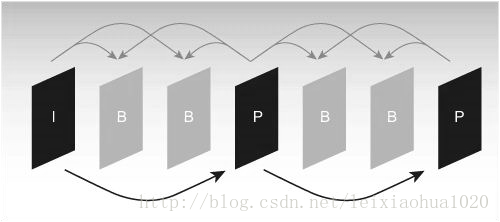
Typowa sekwencja struktury ramek I, B, P.
Jak pokazano na rysunku, ramka I wykorzystuje tylko dane w ramce do kodowania i nie wymaga przewidywania ruchu i kompensacji ruchu podczas procesu kodowania. Oczywiście, ponieważ ramka I nie eliminuje korelacji kierunku czasu, współczynnik kompresji jest stosunkowo niski. W procesie kodowania ramka P wykorzystuje przednią ramkę I lub ramkę P jako obraz odniesienia do kompensacji ruchu, w rzeczywistości koduje różnicę między bieżącym obrazem a obrazem odniesienia. Tryb kodowania ramki B jest podobny do ramki P, jedyną różnicą jest to, że musi on wykorzystywać przednią ramkę I lub ramkę P i późniejszą ramkę I lub ramkę P do przewidywania podczas procesu kodowania. Zatem każde kodowanie ramki P musi wykorzystywać jeden obraz klatki jako obraz odniesienia, podczas gdy ramka B potrzebuje dwóch ramek jako odniesienia. Natomiast ramka B ma wyższy współczynnik kompresji niż ramka P.
(d) Kodowanie mieszane
W artykule przedstawiono kilka ważnych metod kompresji i kodowania wideo. W praktyce metody te nie są rozdzielane i zwykle łączy się je w celu uzyskania najlepszego efektu kompresji. Poniższy rysunek przedstawia model kodowania hybrydowego (tj. Kodowanie transformacyjne + przewidywanie ruchu i kompensacja ruchu + kodowanie entropijne). Model jest szeroko stosowany w standardach MPEG1, MPEG2, H.264 i innych. Z rysunku widać, że bieżący obraz wejściowy musi być najpierw podzielony na bloki, blok obrazu uzyskany przez blok należy odjąć od przewidywany obraz po kompensacji ruchu w celu uzyskania obrazu różnicowego x, a następnie transformacja DCT i kwantyzacja są przeprowadzane dla bloku obrazu różnicowego. Kwantowane dane wyjściowe mają dwa różne miejsca: jednym jest wysłanie ich do kodera entropijnego w celu zakodowania, a zakodowany strumień kodu jest wysyłany do pamięci podręcznej Zapisz w urządzeniu i czekaj na transmisję. Innym zastosowaniem jest zliczanie ilościowe i odwrócenie zmiany sygnału x ', który dodaje wyjście bloku obrazu z kompensacją ruchu w celu uzyskania nowego sygnału obrazu prognozowania i wysyła nowy blok obrazu prognozowania do pamięci ramki.



|
|
|
|
Jak daleko (długie) pokrywy nadajnika?
Zasięg transmisji zależy od wielu czynników. Prawdziwy odległość jest oparta na antenie instalowania wysokość, wzmocnienia anteny, przy użyciu środowiska jak budowa i inne przeszkody, czułość odbiornika, anteny odbiornika. Instalacja anteny wyższsokiego i używania na wsi, odległość będzie znacznie bardziej daleko.
Przykład 5W Nadajnik FM używać w mieście i rodzinnego:
Mam użytku klienta 5W nadajnik FM z anteną GP USA w swoim rodzinnym mieście, a on przetestować go z samochodu, to pokrycie 10km (6.21mile).
Przetestować nadajnik FM 5W z anteną GP w moim rodzinnym mieście, to pokrycie około 2km (1.24mile).
Przetestować nadajnik FM 5W z anteną GP w mieście Guangzhou, obejmować tylko o 300meter (984ft).
Poniżej przedstawiamy przybliżony zakres różnych nadajników FM moc. (Zakres wynosi średnica)
0.1W ~ 5W Nadajnik FM: 100M ~ 1KM
5W ~ 15W FM Ttransmitter: 1KM ~ 3KM
15W ~ 80W Nadajnik FM: 3KM ~ 10KM
80W ~ 500W Nadajnik FM: 10KM ~ 30KM
500W ~ 1000W Nadajnik FM: 30KM ~ 50KM
1KW ~ 2KW Nadajnik FM: 50KM ~ 100KM
2KW ~ 5KW Nadajnik FM: 100KM ~ 150KM
5KW ~ 10KW Nadajnik FM: 150KM ~ 200KM
Jak się z nami skontaktować dla nadajnika?
Zadzwoń do mnie + 8618078869184 LUB
Napisz do mnie [email chroniony]
1.How ile chcesz na pokrycie średnicy?
2.How wieża wysoki z was?
3.Where jesteś?
A my daje bardziej profesjonalnej porady.
O nas
FMUSER.ORG to firma zajmująca się integracją systemów, koncentrująca się na bezprzewodowej transmisji radiowej / studyjnym sprzęcie audio wideo / transmisji strumieniowej i przetwarzaniu danych. Zapewniamy wszystko, od doradztwa i doradztwa, poprzez integrację szaf, po instalację, uruchomienie i szkolenie.
Oferujemy nadajnik FM, nadajnik telewizji analogowej, cyfrowy nadajnik telewizyjny, nadajnik VHF UHF, anteny, koncentryczne złącza kablowe, STL, przetwarzanie na powietrzu, produkty nadawcze dla Studio, monitorowanie sygnałów RF, kodery RDS, procesory audio i jednostki zdalnego sterowania, Produkty IPTV, koder / dekoder wideo / audio, zaprojektowane tak, aby spełniać potrzeby zarówno dużych międzynarodowych sieci nadawczych, jak i małych stacji prywatnych.
Nasze rozwiązanie obejmuje stację radiową FM / analogową stację telewizyjną / cyfrową stację telewizyjną / sprzęt do studia audio-wideo / łącze nadajnika studyjnego / system telemetrii nadajnika / system telewizji hotelowej / IPTV nadawanie na żywo / transmisja strumieniowa na żywo / konferencja wideo / system transmisji CATV.
Korzystamy z zaawansowanych technologicznie produktów dla wszystkich systemów, ponieważ wiemy, że wysoka niezawodność i wysoka wydajność są tak ważne dla systemu i rozwiązania. Jednocześnie musimy upewnić się, że nasz system produktów jest w bardzo rozsądnej cenie.
Mamy klientów nadawców publicznych i komercyjnych, operatorów telekomunikacyjnych i organów regulacyjnych, a także oferujemy rozwiązania i produkty wielu setkom mniejszych, lokalnych i społecznościowych nadawców.
FMUSER.ORG eksportuje od ponad 15 lat i ma klientów na całym świecie. Dzięki 13-letniemu doświadczeniu w tej dziedzinie mamy profesjonalny zespół do rozwiązywania wszelkiego rodzaju problemów klientów. Poświęciliśmy się dostarczaniu wyjątkowo rozsądnych cen profesjonalnych produktów i usług. Kontaktowy adres e-mail: [email chroniony]
Nasza fabryka

Praca IT modernizacja fabrycznie. Zapraszamy do odwiedzenia naszej fabryki, gdy przyjdziesz do Chin.

Obecnie, nie są już klienci 1095 dookoła świata odwiedził nasze biuro Guangzhou Tianhe. Jeśli przyjdziesz do Chin, zapraszamy do odwiedzenia nas.
Na targach

To jest nasz udział w 2012 globalne źródeł Hong Kong Electronics Fair . Klienci z całego świata wreszcie mamy szansę razem.
Gdzie jest Fmuser?
Możesz wyszukiwać te numery " 23.127460034623816,113.33224654197693 ”na mapie google, możesz znaleźć nasze biuro fmuser.
biuro FMUSER Guangzhou znajduje się w dzielnicy Tianhe, który jest centrum Kantonu , Bardzo Blisko do Canton Fair , dworzec kolejowy w Kantonie, xiaobei drogowego i dashatou , potrzebuje tylko 10 minut jeśli wziąć TAXI , Witamy przyjaciół z całego świata do odwiedzenia i negocjować.
Kontakt: Sky Blue
Telefon komórkowy: + 8618078869184
WhatsApp: + 8618078869184
Wechat: + 8618078869184
E-mail: [email chroniony]
QQ: 727926717
Skype: sky198710021
Adres: No.305 pokoju Huilan budynku No.273 Huanpu drogowe Guangzhou Chiny Kod pocztowy: 510620
|
|
|
|
Język angielski: Akceptujemy wszystkie płatności, takie jak PayPal, karta kredytowa, Western Union, Alipay, Money Bookers, T / T, LC, DP, DA, OA, Payoneer, jeśli masz jakiekolwiek pytania, skontaktuj się ze mną [email chroniony] lub WhatsApp + 8618078869184
-
PayPal.  www.paypal.com www.paypal.com
Zalecamy używanie Paypal kupić nasze przedmioty, PayPal to bezpieczny sposób na zakup w Internecie.
Każdy element naszej listy na górze strony dolnej posiada paypal logo, aby zapłacić.
Karta kredytowa.Jeśli nie masz paypal, ale nie masz karty kredytowej, możesz także kliknąć żółty przycisk PayPal, aby zapłacić kartą kredytową.
-------------------------------------------------- -------------------
Ale jeśli nie masz karty kredytowej i nie mają konta PayPal lub trudne do GOT paypal rozliczeniowej, można użyć następujących:
Western Union.  www.westernunion.com www.westernunion.com
Zapłać przez Western Union do mnie:
Imię / Imię: Yingfeng
Nazwisko / imię / nazwisko: Zhang
Pełne imię i nazwisko: Yingfeng Zhang
Kraj: Chiny
Miasto: Guangzhou
|
-------------------------------------------------- -------------------
T / T. Płacić przez T / T (przelew / telegraficzny transferu / Przelew)
Pierwsze INFORMACJE BANKOWE (KONTO FIRMY):
SWIFT BIC: BKCHHKHHXXX
Nazwa banku: BANK OF CHINY (HONG KONG) LIMITED, HONG KONG
Adres banku: BANK OF CHINA TOWER, 1 GARDEN ROAD, CENTRAL, HONG KONG
KOD BANKU: 012
Nazwa konta: FMUSER INTERNATIONAL GROUP LIMITED
Nr konta. : 012-676-2-007855-0
-------------------------------------------------- -------------------
DRUGA DANE BANKU (KONTO FIRMY):
Beneficjent: Fmuser International Group Inc
Numer konta: 44050158090900000337
Bank beneficjenta: China Construction Bank Guangdong Branch
Kod SWIFT: PCBCCNBJGDX
Adres: NO.553 Tianhe Road, Guangzhou, Guangdong, dystrykt Tianhe, Chiny
**Uwaga: Kiedy przelewasz pieniądze na nasze konto bankowe, NIE WPISZ niczego w polu uwag, w przeciwnym razie nie będziemy mogli otrzymać płatności ze względu na politykę rządu dotyczącą handlu międzynarodowego.
|
|
|
|
* To zostanie wysłany w 1-2 dni roboczych gdy zapłata jasna.
* Wyślemy go do paypal adres. Jeśli chcesz zmienić adres, prosimy o przesłanie poprawnego adresu i numeru telefonu na mojego maila [email chroniony]
* W przypadku pakietów jest poniżej 2kg będziemy wysłane pocztą zwykłą pocztą lotniczą, to zajmie około 15-25days do ręki.
Jeśli pakiet jest więcej niż 2kg, wysyłamy przez EMS, DHL, UPS, FedEx szybka dostawa ekspresowa, zajmie około 7 ~ 15days do ręki.
Jeśli pakiet ponad 100kg wyślemy za pośrednictwem DHL lub frachtu lotniczego. To zajmie około 3 ~ 7days do ręki.
Wszystkie pakiety są formą Chiny Guangzhou.
* Paczka zostanie wysłana jako "prezent" i zadeklaruj jak najmniej, kupujący nie musi płacić za "PODATEK".
* Po statku, wyślemy Ci wiadomość e-mail, a dam wam tropi liczbę.
|
|
|
Gwarancja.
Skontaktuj się z nami --- >> Zwróć przedmiot do nas --- >> Odbierz i wyślij kolejną wymianę.
Nazwa: Liu Xiaoxia
Adres: 305Fang HuiLanGe HuangPuDaDaoXi 273Hao TianHeQu Guangzhou Chiny.
Pocztowy: 510620
Telefon: + 8618078869184
Proszę zwrócić na ten adres i napisz swój paypal adres, nazwa, problem na notatki: |
|













